之前看到 running_page 这个 Repo 的里面跑步主页展示,想到刚好自己也有些跑步数据,很想折腾一个自己的跑步页面。奈何小白不知道如何使用 python ,安装依赖总是报错,将报错信息扔给 ChatGPT ,虽然给出了操作建议,但还是搞不定。对照项目的 Readme 指引和视频教程,好几次都是从开始到放弃。
昨天看到两篇文章——使用 GitHub Pages 部署 Running Page 个人跑步主页 和 RUN,都是通过直接 Fork Repo仓库的方式来部署的,于是抱着试一试的态度,上手实践了一下,居然真的成功了。看到跑步数据同步过来,很开心。
简单再回顾一下过程,Fork 仓库后,先修改.github/workflow目录下的run_data_sync.yml文件,下图这部分内容按需修改,RUN_TYPE 字段对应你想同步的数据跑步应用来源。
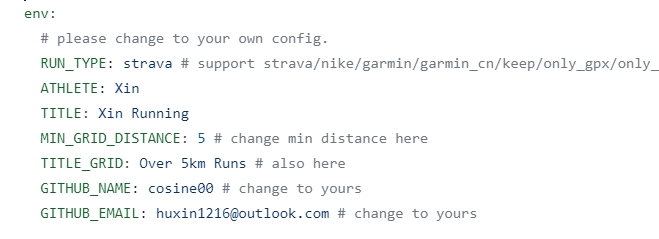
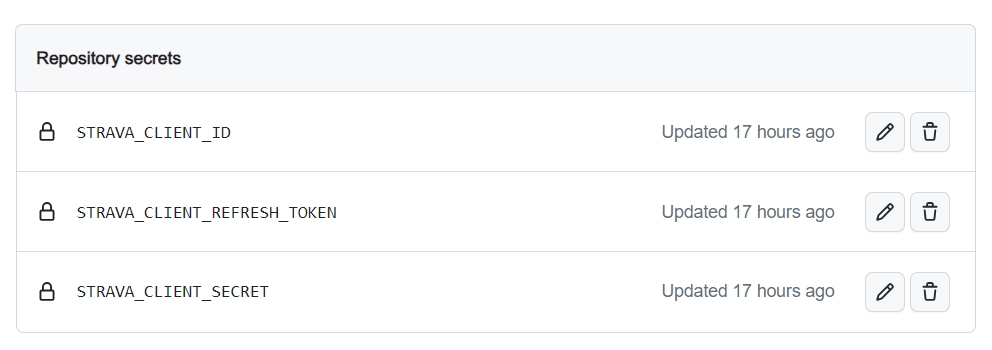
我选择的应用来源是 Strava ,按照获取 Strava 数据的操作步骤,依次获取「STRAVA_CLIENT_ID」、「STRAVA_CLIENT_SECRET」和「STRAVA_CLIENT_REFRESH_TOKEN」三项内容,然后进入仓库的「Settings」>「Security」>「Secrets and variables」>「Actions」,选择顶部的「New repository secret」,将上述三项字段和已获取的值分别填写在此处。
下一步需要将仓库中Yihong大神的已有跑步数据文件删除,分别删除以下路径文件:\assets(里面带年份的文件)、\run_page\data.db 、\src\static\activities.json。删除完毕后进入仓库的「Actions」>「Run Data Sync」>「Run workflow」执行数据同步。
执行完返回刚刚删除数据文件的路径下,可以看到新同步的数据文件已经产生。
最后就是打开Github Page 或者部署到 Vercel 。Done !
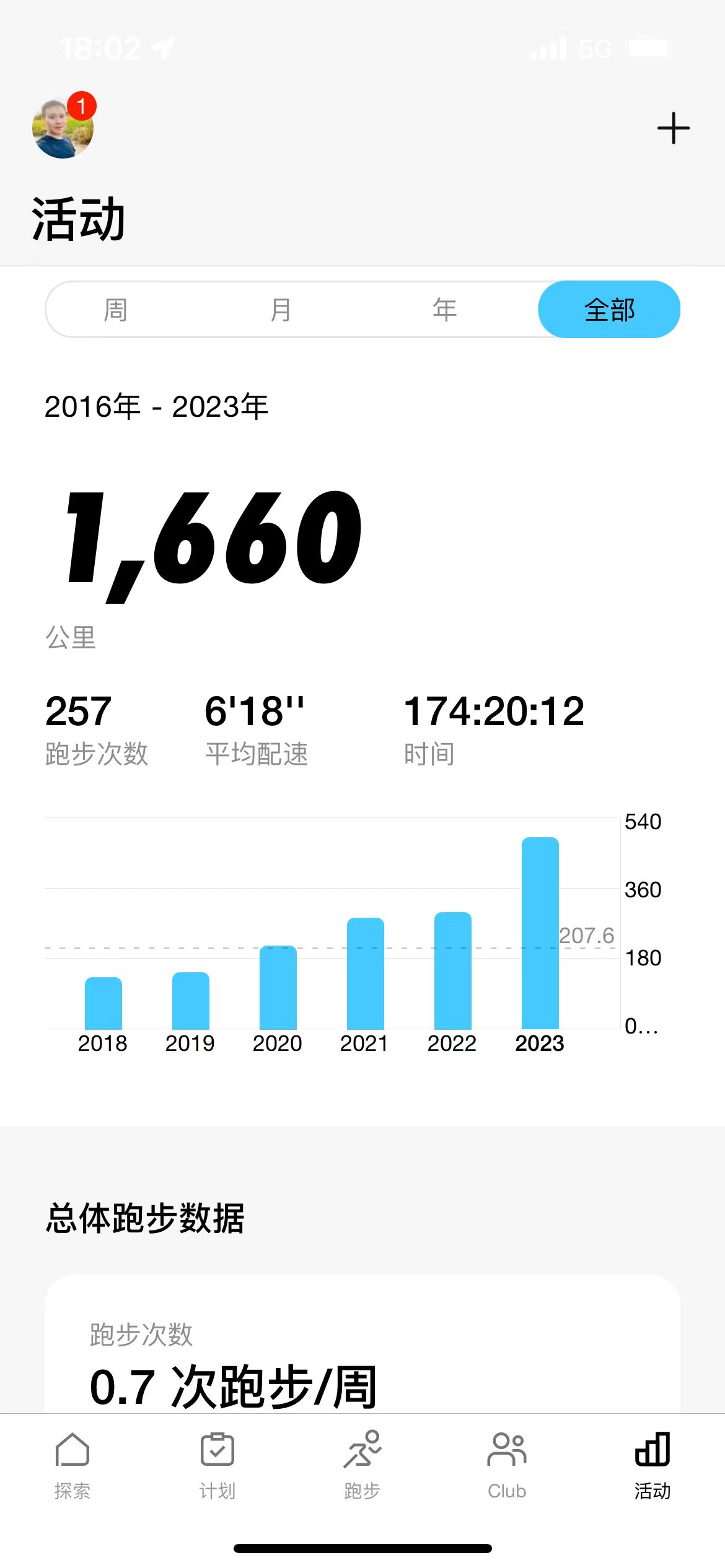
比较遗憾的是以前的跑步数据都是 Nike run club 里面,Nike 的refresh_token 获取不到,没办法同步过来,目前只有从开启 Nike 连接 Strava 之后的已经存储在 Strava 里面的数据。那就慢慢跑下去吧,会积少成多的。

❤